
The years fly by, and we continue to evolve how we design and architect our systems. As we learn more, and technology evolves, so does our processes and design considerations.
In this post I want to make notes of a few best practices I’ve adopted and keep at the top of mind when I engage in new projects that require reliable serverless executions at scale.
There are a ton of other things I would want to add to this post as well, but I’ve chosen the things I consider to be “a-ha” moments for myself throughout my years of building complex and distributed systems.
If you have any tips you’d like to add here, I can link to your posts or tweets - just let me know @zimmergren or in the comments below.
Tip 1. Make use of Dependency Injection
Previously, I wrote about Re-use service instances by Implementing Dependency Injection in Azure Functions. That post walks through how to implement DI with Azure Functions, and also demonstrates the impact this can have at scale.
Key takeaways from the post:
- You can reduce costs.
- You can save resources.
- You can save execution time.
- Coming from a .NET background, it’s easy to adopt DI with Azure Functions.
Read the post: https://zimmergren.net/re-use-service-instances-implementing-dependency-injection-di-in-azure-functions/
Tip 2. Design for short executions
Reasoning 1: Built-in timeouts.
There are built-in timeouts for Functions, depending on what plan and version you’re on. As of this writing, in March 2020, this is what the table look like:
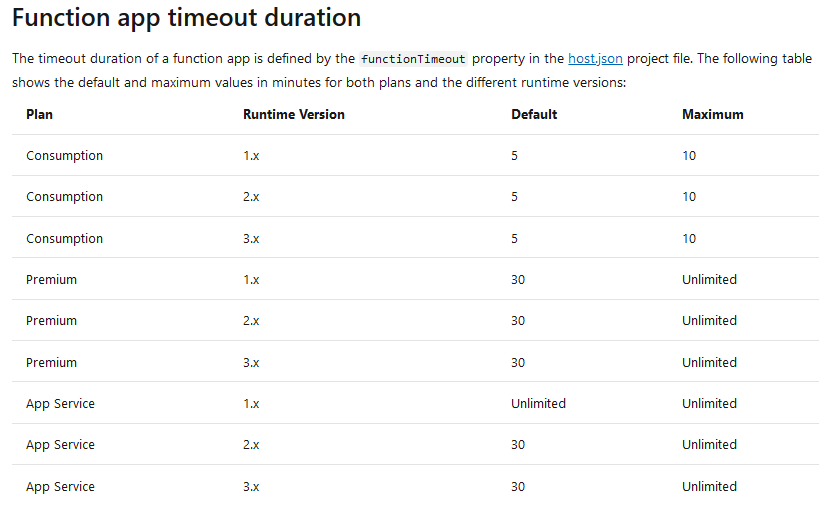
Function app timeout duration, from Microsoft.com
This gives us a good overview of when we need to consider the timeout of our functions. For example, you can see that any version of Azure Functions running on the Consumption plan, can only run for a maximum of 10 minutes before it’s killed.
I’d urge you to bookmark this page, and read more about any changes here.
Reasoning 2: Blocking calls, increased risk for failed executions
With any task that is running for a long time, there’s a risk that it’s interrupted by network errors, dependent services being unavailable, any type of transient faults, service quotas being imposed on any of the dependent services, and many other reasons in modern cloud infrastructure and development.
Keeping the Functions simple, and implementing a message- or event-based pattern that can automatically fan out and fan in (with or without Durable Functions), is a good pattern to adopt if you expect a lot of work to be done by a function, and that it might run over a longer time period.
Queues in any form are a good option to increase the agility, longevity and resilience of your functions. If a message cannot be processed, ensure that you have the logic in place to re-process the message again.
Tip 3. Design with the right messaging- or event-service
Building scalable solutions can be done in a lot of different ways. If you have make a decision to go down the route of building an event- or message-based solution, where you can easily scale in and out your systems based on the active workload, there’s a couple of things to consider.
A message is more like sending the actual data. While an event would tell you that something has changed or occurred.
There’s Azure Event Grid, Event Hubs, Service Bus, Storage Account Queues, and a plethora of other options - not to mention all the third-party options available in the Marketplace, or outside of it…
So, there’s many options for high-scale solutions, and it comes down to all the variables that your system need to handle. The following links are my go-to-links for when you need to make these decisions, and I use them as a starting point for further dialog about requirements and technical design:
- Microsoft: Choosing the right Azure messaging service for your data
- Microsoft: Comparing Storage Queues and Service Bus Queues (Recommended)
- Microsoft: Choose between Azure Event Grid, Event Hub, Service Bus
Tip 4. Design with At Least Once delivery in mind
Expect that a message is processed at least once, and design your systems with this in mind.
If you use event processing, the Azure Functions guarantees at-least-once delivery, and your code should be aware that the same message could be received more than once.
This is a design pattern that allows us to preserve data integrity and the stability of our overall system at large, but if we’re not aware of the fact that a message can arrive more than once, we need to revisit our design decisions.
We don’t have to handle it logically every time, depending on what type of message it is.
Example scenario:
- Your system sends an e-mail upon receiving a specific message.
- Your pick up the message, format a nice message, send through some mail service provider. Voila.
Except, that if this message comes in more than once (at-least-once delivery), how do you ensure that you don’t send the same message twice, or more?
At scale, these are things to consider, and something to think about in code. I’ve had my fair share of struggles with what I thought was bad concurrency management, but in the end it was the design of the system, and my own logic that was faulted.
To take this into consideration, there’s a great article about Designing Azure Functions for identical input over at Microsoft Docs.
Tip 5. Build async, and avoid blocking code
In the past years, I’ve built a lot of scalable, distributed systems. Usually they have involved services like Azure Functions, Azure Container Instances, Azure Kubernetes Services, and more.
What I have experienced at-scale is that synchronous vs. asynchronous execution choices matters. Today, I tend to design all my Azure Functions with an asynchronous execution model, to avoid any blocking calls, but it does come with some gotchas.
- Never use the
.Resultproperty. - Never call the
.Wait()method. - Never block calls inside of a Task.
This can quickly lead to thread exhaustion. Especially at scale with many concurrent executions on your Function host.
Read more about why that is bad: https://stackoverflow.com/questions/57611394/does-using-async-await-avoid-thread-exhaustion
A good tip to analyze how well you handle async code, is to use the AsyncFixer NuGet or Visual Studio extension.
Tip 6. Keep logs
While this shouldn’t be a headline here, it is worth mentioning time and time again. Keep logs. I mean of everything - auditing your code and reviewing logs can help a lot in figuring out where things went sideways, or if automation tasks came through properly or not.
- Log all failures. Period.
- Optionally log successes.
I mention optionally log successes, because it depends on the data ingestion you get. My functions process hundreds of millions of items per month collectively, and keeping 500M “success” entries doesn’t make sense unless they contain vital information that I need, which they don’t.
Logging to Application Insight is highly recommended for Azure Functions. See the supported built-in features here.
Tip 7. Design for concurrency of HTTP Functions
Concurrency is always something to consider in a distributed application. With Azure Functions, we can distribute our workload a lot, and we have control over “how much concurrency” we want to configure - not everyone is aware of this, so let’s dive into that for a moment.
Concurrency configuration can be seen as a way to self-throttle your Functions, to avoid running out of resources in the Function host.
Using the configuration value maxConcurrentRequests in the host.json file, we can control this more granulary. Here’s what the docs say:
The maximum number of HTTP functions that are executed in parallel. This value allows you to control concurrency, which can help manage resource utilization. For example, you might have an HTTP function that uses a large number of system resources (memory/cpu/sockets) such that it causes issues when concurrency is too high. Or you might have a function that makes outbound requests to a third-party service, and those calls need to be rate limited. In these cases, applying a throttle here can help.
*The default for a Consumption plan is 100. The default for a Dedicated plan is unbounded (-1).From docs.microsoft.com
Things to consider:
- Settings in host.json apply to all functions within the app, withing a single instance of the Function. This means that if you have 5 functions in your Function App, all of them shares the concurrency configuration, and if you configure 50 concurrent requests, the 5 functions will share that quota. It’s not per app inside the Function App.
- If you scale out your Function App to 5 instances, you will get (5 * 50) = 250 concurrent requests.
Design your Function Apps for scale, design for concurrency and with good load testing you should find the sweet spot for your applications.
Tip 8. Separate the Function storage account from others
With Azure Functions, you bind it to an Azure Storage Account. In order to stay true to good practices, we should separate our own storage account and data from the storage account used by Azure Functions.
This helps to:
- Increase performance at scale (less hammering on the same storage).
- Separate your business logic from the processing of the Functions.
It isn’t always ideal to split the storage accounts, but in the end if you’re designing a highly scalable solution, it will show the results fairly quickly. Storage accounts come with limits, throttling, concurrency and throughput considerations as anything else in the cloud - by separating these concerns, we lessen the burden of a single storage account.
Tip 9. Function idempotency
Let’s be honest. That word is not something I knew a year ago. I might have known about underlying reasons for why we want to “Design Azure Functions for idempotency”, but I had no idea that this was a thing.
Microsoft have a great post about “Designing Azure Functions for identical input” which re-iterates a lot of the pain points I’ve addessed over the years, too.
Read it here, then read this post on Medium by Tsuyoshi Ushio, about how it can work in practicality.
Microsoft explains it with a few simple words:
Functions should be stateless and idempotent if possible. Associate any required state information with your data. For example, an order being processed would likely have an associated
statemember. A function could process an order based on that state while the function itself remains stateless.
Idempotent functions are especially recommended with timer triggers. For example, if you have something that absolutely must run once a day, write it so it can run anytime during the day with the same results. The function can exit when there’s no work for a particular day. Also if a previous run failed to complete, the next run should pick up where it left off.
Tip 10. Design with Security on top of your mind
Designing anything these days require you to really think about security from the get-go. There is no reason to linger or delay thoughts around how to secure your resources. With 2019 being unprecedented in the number of data breaches occurred to organizations worldwide, it’s no wonder that everyone are on their toes and trying to ramp up their security game.
While building Azure Functions, you also need to consider security. Designing how they are deployed, who can access them and the infrastructure, and how the code works and what it can access, and so on.
Authorization and Authentication
With Azure Functions, you can use different scopes of Authorization on the Function, or use Authentication tied to the Function App.
Secure the HTTP endpoints for Development and Testing
Ideally you’ll use Authorization in development- and testing scenarios only, and use Authentication and access restrictions in any type of production workload.
Authorization scopes:
- Function. Requires a specific key to request a specific function (HTTP triggered).
- Host: Requires a specific key, but can trigger any function in the Fuction App.
Read about how to implement Authorization for your functions.
Secure the HTTP endpoints for Production
While Authorization is cute, what you ideally want is Authentication to block requests already before they hit the Functions. There’s a wide range of production-ready capabilities that can work at scale. Which option that suits your requirements the best is something only you know. Here’s a couple of ideas for production workloads.
- Turn on App Service auth to enable Azure AD (or any third party auth provider) to authenticate the clients calling your function.
- Use API Management.
- Use an Azure App Service Environment (ASE), which also enables you to use a WAF (Web Application Firewall).
- Use an App Service Plan where you restrict access, and implement Azure Front Door + WAF to handle your incoming requests.
- Require clients to authenticate with client certificates.
What the docs are missing as of today is the recently launched Azure Front Door + Web Application Firewall configuration for your Azure Functions. It looks like this in the UI:
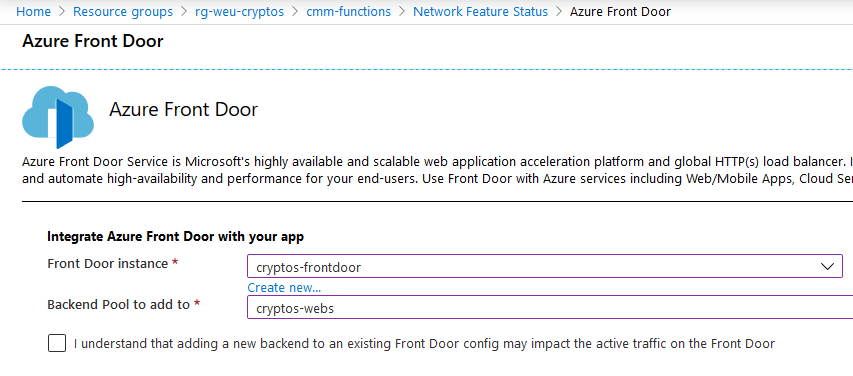
Zimmergren’s crypto project with a dialog to integrate Azure Front Door with your Function App
Microsoft docs: Secure an HTTP endpoint in Production
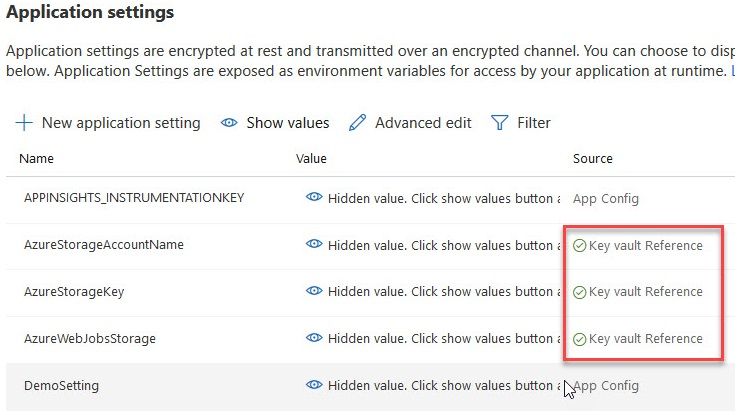
Secure application settings with Key Vault references
I have previously written about the topic of securely storing your application configuration in an Azure Key vault rather than directly in your App Settings.
Key takeaways are:
- You don’t want plain-text configuration values of sensitive data.
- There’s no reason to take lightly on security. Ever.
- You can utilize managed identity to allow the Function App to “Get” secrets from the Key Vault, but nothing else.
The post is available for full reading here: https://zimmergren.net/azure-functions-key-vault-reference-azurewebjobsstorage/
Make use of Managed Identities with Azure Functions
While we’re on the topic of security, let’s also briefly mention that with Azure Functions, as with any App Service, you can enable Managed Identities.
This enables you to:
- Enable your Function App to access resources (Key Vault, Storage Account, ..) without requiring a specific global access key or connection string.
- Enables you to get a full audit trail in the logs, displaying what identity executed a request to your resources, as opposed to “Connection String 1” or “Key 1” was used, it will now way “Identity 123” was used, which you then know belongs to “Function 123”.
- RBAC is awesome, and using managed identities you can granularly control exactly what the Function App should have access to, if anything at all.
Here’s a great post about using Managed Identities.
Summary
The cloud and serverless isn’t a magical place where everything works. Quite the contrary, for an enterprise-grade and highly distributed application to work, there’s a lot of design considerations to learn from.
Severless doesn’t mean there’s no servers. It just means that you don’t have to manage those servers - the code still runs on the hardware in the cloud, which in reality are data centers on the ground, and they live by the same constraints that all other data centers do.
I hope these tips based on my real-world experience can help, and as always, if you see something missing please let me know and I can update the post with your tips and link to your blog/twitter.
Thanks for reading!
Tobias.
Header photo by Alexandru Acea on Unsplash

Comments are closed