
In this post, I am talking about how we can practically make use of the Azure File share that is mounted to our containers in AKS. I’m examining a PoC of how you can query a SQLite database hosted on an Azure File share, accessed from multiple containers at a huge scale simultaneously. It’s fun, tag along.
This is a mini-series with two parts.
- How to: Mount an Azure Storage File share to containers in AKS.
- (this post) Processing data from SQLite hosted in an Azure File share, running in Azure Kubernetes Services.
I’ve simplified the sample code for this blog post by creating a standalone single C# console app, running as a container image in Azure Kubernetes Services, which we can scale out as we please.
Background
Knowing we are running a simplified sample code, I’ve removed all batching, optimizations and re-constructed the core parts of fetching data from the SQLite database into an example that is as easy as it can get. From there, you can build whatever you want out of it.
Assumptions
- We want to query a big SQLite database.
- We need to calculate/process the returned results and insert them in a more interpretative format.
- We need to be able to process the SQLite database quickly, even if it has hundreds of gigabytes or more of compressed data.
- We don’t want to write back to the SQLite database; we want to write into an Azure Table Storage for performance, security, and future integration reasons.
- We don’t want to write back to the SQLite database due to concurrency issues, and due to slow operations with concurrent read/write operations. Running on an Azure File share, it’s not optimal for hundreds or even thousands of processing containers to hammer it with write activities simultaneously. It will not work well. Yes, I’ve tried - perhaps I will share those details in another post, if anyone’s keen on learning more - for now, we use read-only and only query the database.
- We want to distribute the workload horizontally across nodes, and vertically on each node, without affecting or changing any code.
- Due to simplifying this code a lot, there’s no implementation of queues for distributing the workload properly, we’re just querying the SQLite database randomly at intense rates to prove that it works.
- You should have indexes in your SQLite database. With the more complex tests I’ve done that uses a couple of
wherestatements, it takes more than 25x longer than with indexes. That’s an incredibly high penalty for not using indexes, so there’s no reason to avoid them. - You need to decide whether you’re using an Azure Storage Account in Standard or Premium tiers, as the performance differences can be substantial depending on your architecture.
Scale test
This is the humble scale I’ve tested:
- 15 nodes in my AKS clusters
- 750 containers spread across multiple deployments
- (Math time: this gives us 50 containers running per node)
I didn’t time it, which I now regret because I think the numbers would be fun to crunch here.
The results after running in hammer-time-mode:
- More than 50 000 000 successful read-only queries to SQLite on Azure File share
- More than 50 000 000 successful transactions to Azure Table Storage
- 0 logical failures
Note: Due to basic-tier storage accounts, the performance can suffer due to File IO operations in this scenario. A tip then is to batch the queries and optimize the query load, to reduce the file operations required on the storage account.
Important: With Azure File shares (at least in the Standard tier, which is the only available tier right now), performance is limited by the official scale targets (https://docs.microsoft.com/en-us/azure/storage/files/storage-files-scale-targets), and this will have an impact if you are using bigger files and larger amounts of data, and/or more transactions.
It’s great to be able to run this performance test with a distributed workload, but even with this setup the limits of Azure Files will present itself in the standard tier if you don’t plan cautiously around the scale targets.
Final note: Premium Files is in public limited preview, and it boosts performance a lot. I’ve used it in some of my tests, and see an increase in performance. Read more: https://azure.microsoft.com/en-us/blog/premium-files-pushes-azure-files-limits-by-100x/
Show me the Code
Let’s call this a SQLite processing machine. You can make up your own silly name if you’d like. This is mine, and I’m sticking to it.
Grab the dummy code from GitHub
Pretty straight forward. It’s also available on GitHub, including the yaml files from the previous blog post.
The core part of the app is that we fetch data from SQLite and insert into an Azure Storage Account.
We iterate indefinitely and keep on querying the SQLite database. This is a query that returns a single record on every iteration without batching or query optimizations. Dumb, but proves that the system can handle it.
public DummyQueryData QueryDatabaseAndReturnANewObject()
{
// Mode=ReadOnly to avoid concurrency issues with writing to the file share. We only need to process read scenarios.
var connection = new SqliteConnection($"{_connectionString};Mode=ReadOnly");
connection.Open();
int indexKey = new Random().Next(1, 1000000);
string sql = $"SELECT * FROM contact WHERE Id = {indexKey}";
using (SqliteCommand command = new SqliteCommand(sql, connection))
{
Stopwatch watch = new Stopwatch();
watch.Start();
using (SqliteDataReader reader = command.ExecuteReader())
{
while (reader.Read())
{
watch.Stop();
return new DummyQueryData(watch.Elapsed.TotalSeconds, Environment.MachineName);
}
}
}
connection.Close();
return null;
}
The Program.cs simply fetches the dummy object and inserts it into the Azure Storage Table. Every time. Like this:
private static void ProcessReadOnce()
{
var newDummyObject = _sqliteHelper.QueryDatabaseAndReturnANewObject();
// Insert dummy object into Azure Storage Table in order to transition from the sqlite database into the table storage.
// Dummy data to just prove that the distributed processing of reading the sqlite database works.
TableOperation insertOperation = TableOperation.Insert(newDummyObject);
_table.ExecuteAsync(insertOperation).Wait();
// Simple logging to console, if you want to view this running distributed in the cloud.
// Aadded machine name to see when it's ran by different containers, which will display the container that executed the command.
string output = $"{DateTime.UtcNow:u}. QUERY: {newDummyObject.ExecutionTime} sec. MACHINE: {newDummyObject.MachineName}";
Console.WriteLine(output);
}
Build, Publish, Push and Deploy the demo application
I am not discussing how you configure and set up your Azure Container Registry (ACR), as I’ve talked about it before.
We will now build, publish, push and deploy our demo application so it runs in Azure Kubernetes Services.
If you have your ACR ready, let’s get down to it.
1. Get, build and publish the source code (or use your own)
Grab source code from the GitHub repo, or use your own code if you’d like.
Build and publish the project:
dotnet build && dotnet publish
It should build and publish the binaries.
dotnet build and dotnet publish to produce the binaries we need for our deployment in docker containers
2. Define Dockerfile contents
My Dockerfile contents look like this for the sample, and is located in the project root folder:
FROM microsoft/dotnet:2.2-runtime
WORKDIR /app
COPY ./bin/Debug/netcoreapp2.2/publish .
ENTRYPOINT ["dotnet", "Zimmergren.AksFileShareDemo.dll"]
As you can see, I’m using the microsoft/dotnet:2.2-runtime image as a base. See the latest version available from the Microsoft image repo.
3. Build docker image and push to your Azure Container Repository
Run docker build:
docker build . -t mytestapp
docker build . -t mytest app | builds the docker image with our new binaries
Login to your ACR:
docker login your-acr-url.azurecr.io
Tag your new image and push it to ACR:
docker tag mytestapp your-acr.azurecr.io/demoapp:demo
docker push your-acr.azurecr.io/demoapp:demo
docker tag and docker push to shoot our image up into our Azure Container Registry
Great, you’ve compiled, published, docker built, tagged and pushed the image. Let’s run it!
Deploying to Kubernetes in Azure
In my previous blog post I mentioned how to configure the deployment and create a secret to connect to your Azure File share form your containers.
You can use that approach, just change the details in the yaml files to point to your newly published container image in your ACR, and off you go.
Because I’ve described it in the previous post, I’m not re-iterating how to deploy it again here. Please read that post to see how you can get the next points covered if you haven’t already.
Examine the running app and make sure it works
Let’s see that the app is running, and peek into the logs:
> kubectl get pod -n blogdemodeployments
NAME READY STATUS RESTARTS AGE
deployment-azurestorage-test-68b78cd79-qc66b 1/1 Running 0 2mWe can see there’s one pod running. Let’s make sure the logs display what we want, so we know it works:
> kubectl logs deployment-azurestorage-test-68b78cd79-qc66b -n blogdemodeploymentsWorks:
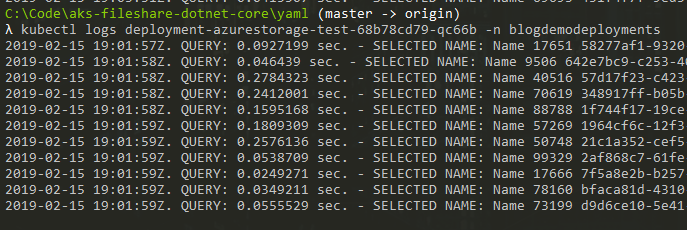
Logs from a container, mounted with an Azure File share to get data from a sqlite database.
Scale-out our system
Since we’re working with deployments, and our deployment is the tie to the Azure File share mount, we can scale out the deployment and all pods will automatically have access to that mount - so all the containers can collaborate on processing the data I have in my SQLite database.
> kubectl scale deployment deployment-azurestorage-test -n blogdemodeployments --replicas 50
Result:
deployment.extensions "deployment-azurestorage-test" scaledReview data
You can now see that multiple containers/pods are running in your deployment, and peeking into the logs of any one of them will display how long the query took and then the machine name next to it
In Azure Table Storage, there’s a lot of data now, and there’s a table demotable that in my sample has more than 500M items, because as of this writing it’s already been running for quite some time.
Summary
In this blog post, I’ve talked about SQLite hosted in an Azure File share. There are some considerations here.
- The code is connecting to SQLite with Read Only, which works well thus far.
- Writing in this cadence isn’t optimal, and doesn’t work quite as well with an Azure File share, and you might consider other options for that scenario.
- With read only we don’t get any concurrency issues. This is a good thing. Avoid writing at this scale if you’re on an Azure File share. In my experiments, it didn’t work very well and there were at least a 10-20% error margin, which is entirely unacceptable.
- If you seriously want to throw a big bunch of data into Azure Storage tables, please read the documentation: Guidelines for table design - specifically the Table Design Patterns. This will help you build code, and infrastructure that scales well.
- C# built on top of .NET Core scales well in containers and micro-services.
- Don’t neglect the scale targets of Azure File shares.
Well, this experiment has come to an end - it has been fun to let it run for a while and hammer the heck out of my Azure Storage account’s file share, hammer insert operations into Table Storage and to generally test the scale-out of my Kubernetes clusters.
For reading about how to store secrets in Azure Key Vault more securely, check out my friend Thorsten’s blog posts on that topic:

Comments are closed